After a lot of testing and performance profiling, on Friday I released RelStorage 1.1. On Saturday, I was planning to blog about the good news and the bad news, but I was unhappy enough with the bad news that I decided to turn as much of the bad news as I could into good news. So I fixed the performance regressions and will release RelStorage 1.1.1 next week.
The performance charts have changed since RelStorage 1.0.
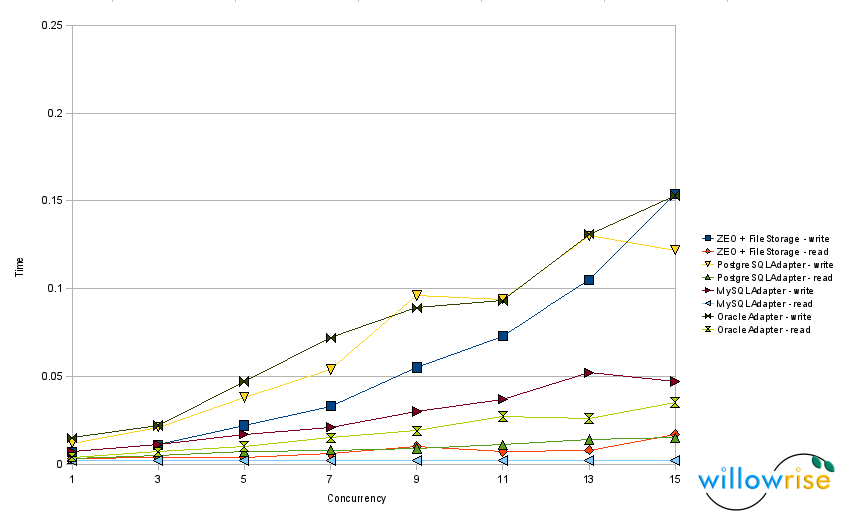
Chart 1: Speed tests with 100 objects per transaction.
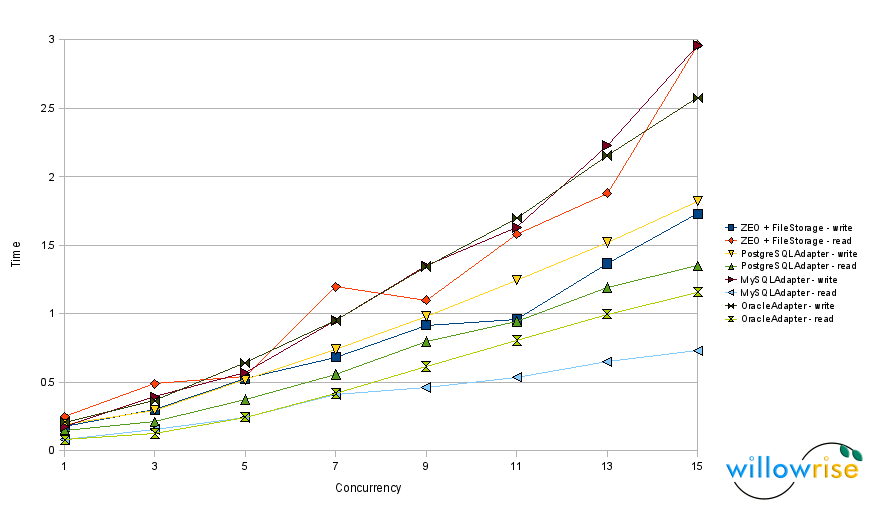
Chart 2: Speed tests with 10,000 objects per transaction.
I’m still using 32 bit Python 2.4 and the same hardware (AMD 5200+), but this time, I ran the tests using ZODB 3.8.1.
The good news:
- Compared with RelStorage 1.0, reads from MySQL and Oracle are definitely faster. In some tests, the Oracle adapter now reads as quickly as MySQL. To get the Oracle optimization, you need cx_Oracle 5, which was just released this week. Thanks again to Helge Tesdal and Anthony Tuininga for making this happen.
- Loading 100 objects or less per transaction via MySQL is now so fast that my speed test can no longer measure it. The time per transaction is 2 ms whether I’m running one ZODB client or 15 concurrently. (The bad news is now I probably ought to refine the speed test.)
The bad news in version 1.1 that became good news in version 1.1.1:
- The Oracle adapter took a hit in write speed in 1.1, but a simple optimization (using setinputsizes()) fixed that and writes to Oracle are now slightly faster than they were in RelStorage 1.0.
- MySQL performance bugs continue to be a problem for packing. I attempted to pack a 5 GB customer database, with garbage collection enabled, using RelStorage 1.1, but MySQL mis-optimized some queries and wanted to spend multiple days on an operation that should only take a few seconds. I replaced two queries involving subqueries with temporary table manipulations. Version 1.1.1 has the workarounds.
The bad news that I haven’t resolved:
- Writing a lot of objects to MySQL is now apparently a little slower. With 15 concurrent writers, it used to take 2.2 seconds for each of them to write 10,000 objects, but now it takes 2.9 seconds. This puts MySQL in last place for write speed under pressure. That could be a concern, but I don’t think it should hold up the release.
Of the three databases RelStorage supports, MySQL tends to be both the fastest and the slowest. MySQL is fast when RelStorage executes simple statements that the optimizer can hardly get wrong, but MySQL is glacial when its query optimizer makes a bad choice. PostgreSQL performance seems more predictable. PostgreSQL’s optimizer seems to handle a subquery just as well as a table join, and sometimes SQL syntax rules make it hard to avoid a subquery. So, to support MySQL, I have to convert moderately complex statements into a series of statements that force the database to make reasonable decisions. MySQL is smart, but absent-minded.
The ZEO tests no longer segfault in ZODB 3.8.1, which is very good news. However, ZEO still appears to be the slowest at reading a lot of objects at once. While it would be easy to blame the global interpreter lock, the second chart doesn’t agree with that assumption, since it shows that ZEO reads are slow regardless of concurrency level. ZEO clients write to a cache after every read and perhaps that is causing the overhead.
I will recommend that all users of RelStorage upgrade to this version. The packing improvements alone make it worth the effort.