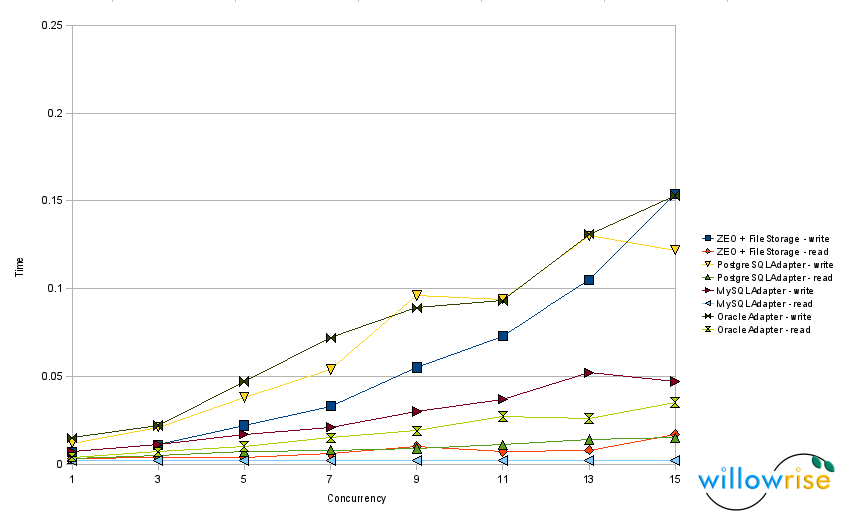
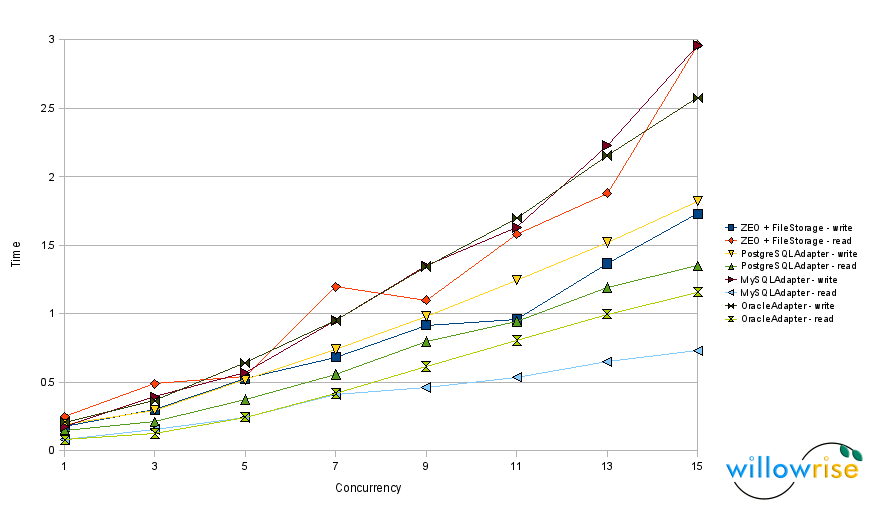
I’ve been working on packing a 6.5GB production database based on RelStorage and MySQL 5.0. It contains 6.4 million objects, meaning “select count(1) from current_object” returns 6426879. I would call this a moderately sized database. When I first approached it, it had not been packed for at least 3 months. At first, I could not pack it, because RelStorage was using statements that MySQL mis-optimizes. I will discuss how I fixed the problem.
The first time I tried to pack this database, the pre_pack phase took several hours before I stopped it by killing the Python process. I studied the problem using “show processlist” and the MySQL docs online. I found a statement in RelStorage that MySQL mis-optimizes. I tried again and it still took too long; this time I discovered that a workaround I had applied earlier for a mis-optimized query did not actually help this instance of MySQL. I decided to make the workaround more robust by using an explicit temporary table.
Then, on Saturday, I started a pack again. The pre_pack phase completed in less than an hour this time and the final phase began. The final phase gets from the pre_pack phase a complete list of objects and states to delete; all it really has to do is delete them. I let it run all weekend. Today (Monday), using “show processlist” again, I measured 17 seconds per transaction, with 26,000 transactions to go. With a 50% duty cycle, this would have taken about 10 days! (The 50% duty cycle is a configurable parameter that causes RelStorage to periodically sleep during packing, allowing other clients to write to the database without significant interruption.)
I read up on the delete statement. It turns out that delete with a subquery is often very expensive in MySQL. I converted the delete statements to use a table join instead of a subquery, and the time per transaction dropped from 17 seconds to about 3 milliseconds. This time the pack finished in minutes.
Does this mean I should optimize every statement this way? Certainly not. The SQL syntax I had to use to optimize MySQL is not portable, so I had to sacrifice portability, readability, and maintainability, in order to gain acceptable performance. I will only make that sacrifice when necessary.
I am very happy that I did not try to optimize this code until I was in a position where I could properly measure the performance with millions of real objects. If I had optimized prematurely, I would have focused on micro-optimizations that might have only doubled or tripled the performance. By waiting until the time was ripe, I multiplied the pack performance by a factor of at least 5,000, with only a few days of work and only minor code changes. Next time someone asks why premature optimization is so evil, I will try to remember this experience. Most of the best software developers I know skip micro-optimizations and focus on readability instead, helping to ensure that much larger optimizations will be possible later.
Note that during my optimization work, I never once needed to interrupt the main site nor restart MySQL. I only restarted my own Python program repeatedly. I doubt anyone else knew there was a pack going on.